5. World Wide Web¶
Le World Wide Web (WWW), littéralement la « toile (d’araignée) mondiale », est un système qui permet de consulter avec un navigateur, à travers l’Internet, des pages accessibles sur des sites.
5.1. Historique¶
Pendant ses premières décennies (jusque dans les années 90), seuls les universitaires, les militaires, certaines entreprises et une communauté d’enthousiastes (largement issue du mouvement hippie) utilisaient Internet. Les utilisations principales étaient la discussion écrite (le chat dans un terminal), la connexion sur un ordinateur à distance, l’email et le transfert de fichiers entre ordinateurs.
Pour aller chercher un fichier se trouvant sur un autre ordinateur, il fallait savoir exactement sur quelle machine celui-ci se trouvait et où il se situait dans cette machine. Il fallait donc établir des listes de ressources et de leur location dont la maintenance et l’utilisation étaient fastidieuses.
C’est en voulant résoudre ce problème que Tim Berners-Lee, un scientifique anglais du Conseil Européen de la Recherche Nucléaire (CERN) à Genève, a développé les technologies du Web entre 1989 et 1991. Celles-ci se sont rapidement développées après que le CERN les ait gratuitement mises à disposition du public. Des centres de recherche, universités, entreprises (d’informatique et de média) et d’autres organisations ont créé leur site web afin de pouvoir facilement diffuser des informations par ce canal. Ceci offrait un usage supplémentaire de l’ordinateur dont les foyers se sont équipés massivement, diffusant ainsi l’accès à Internet au sein de la population américaine et européenne.
5.2. Les technologies du Web¶
Le web repose sur trois technologies mises ensemble et qui permettent de naviguer dans une “toile” de documents. La première, l’URL, spécifie un format permettant de spécifier la localisation d’un document. La seconde, le protocole HTTP, permet de demander et de recevoir un document identifié par son URL. La troisième, le langage HTML, permet de décrire le contenu d’un document (une page web) pouvant contenir des liens vers d’autres documents spécifiés par leur URL.
Ces trois technologies sont rassemblées dans un navigateur web, un programme qui permet de
spécifier une page web à visiter en indiquant son URL, typiquement dans une barre de navigation
demander la page web au serveur correspondant et la réceptionner en utilisant le protocole HTTP
afficher le contenu de la page web (décrite au format HTML), y compris les liens cliquables permettant d’afficher d’autres pages web.
Document historique
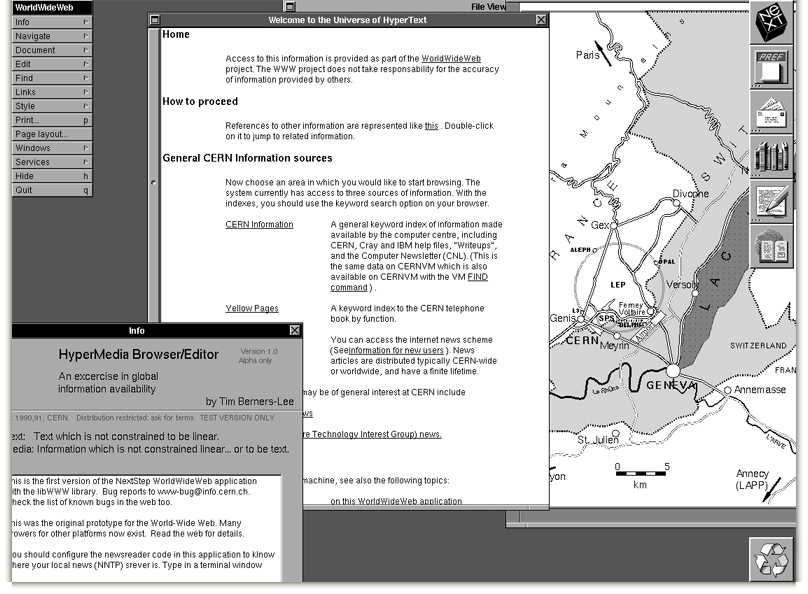
Fig. 5.9 Un des premiers navigateurs web développé par Tim Berners-Lee. Les images s’affichaient sur des fenêtres séparées.¶
URL¶
L’URL (Uniform Resource Locator) est une manière de spécifier la localisation d’un document disponible sur Internet.
Un exemple d’URL peut être par exemple : https://www.champignons.ch/fichiers/fr/contact.html
Une URL comporte trois parties, qui sont les suivantes dans notre exemple : https://, www.champignons.ch et /fichiers/fr/contact.html.
Le protocole, dans notre exemple
https, indique le protocole utilisé pour avoir accès à la ressource. Pour le web, ce protocole est toujourshttpouhttps, sa version sécurisée. Mais l’URL étant aussi utilisée en dehors du web, il y a d’autres protocoles possibles, par exempleftppour faire du transfert de fichier.L’hôte spécifie la machine (ou le serveur) où aller chercher le fichier. Cela peut être un nom de domaine, mais également une adresse IP. Dans notre exemple, c’est le nom de domaine
www.champignons.ch. Un exemple d’adresse IP est127.0.0.1.Le chemin indique quel fichier on souhaite obtenir de la part du serveur. On part de la racine “/” (connue du serveur) et on descend dans l’arborescence selon les répertoires indiqués. Par exemple
/fichiers/fr/contact.htmlest le fichiercontact.htmlqui se trouve dans le répertoirefrqui se trouve lui-même dans le répertoirefichiers.
Une URL se compose donc de la manière suivante :
protocole://hôte/chemin
Dans le protocole HTTP, si le chemin est un répertoire (et pas un fichier), le fichier par défaut index.html présent dans ce répertoire est envoyé par le serveur.
HTTP¶
HTTP (acronyme de HyperText Transfer Protocol) est le protocole qui régit la manière dont un client web (par exemple le navigateur web de Alice) et un serveur web (par exemple le site www.champignons.ch) vont interagir l’un avec l’autre.
Par exemple si le client demande au serveur de lui envoyer la page web accueil.html, il lui enverra la requête GET suivante:
GET accueil.html HTTP/1.1
ce qui signifie “envoie-moi la page accueil.html avec la version 1.1 du protocole HTTP”. S’il trouve la page en question, le serveur pourra alors envoyer la réponse suivante:
HTTP/1.1 200 OK suivie de diverses informations ainsi que la page web demandée. Le code 200 OK indique que la requête peut
être honorée.
Si la page accueil.html n’existe pas, alors le serveur pourra l’indiquer au client en envoyant la réponse suivante:
HTTP/1.1 404 Not Found
Le navigateur web pourra alors afficher l’“erreur 404” au pour l’utilisateur.

Fig. 5.10 Le serveur retourne un message d’erreur s’affiche lorsqu’on demande une page qui n’existe pas.¶
Il y a d’autres sortes de requêtes que le client peut envoyer au serveur, par exemple POST pour envoyer une information du client au serveur, utilisé par exemple lorsqu’on remplit un formulaire en ligne.
Si un utilisateur utilise le protocole HTTP pour surfer sur le web, une tierce personne qui a accès au trafic sur Internet peut savoir quelle page web a été visitée par cet utilisateur et ce que le serveur lui a envoyé comme information (par exemple des messages privés). C’est pourquoi on utilise généralement plutôt le protocole HTTPS qui encrypte les requêtes et réponses HTTP. Ainsi un observateur peut toujours savoir avec quel site on communique lorsqu’on surfe sur le web en regardant l’entête IP, mais ne pourra pas connaître les détails des pages demandées et transmises.
HTML¶
HTML (HyperText Markup Language) est un langage de description des pages web. Il permet de spécifier le contenu et l’apparence d’une page web afin que le navigateur web puisse l’afficher. Supposons par exemple que le site www.champignons.ch envoie à Alice une page web contenant le nom d’un champignon ainsi qu’une photo de celui-ci. Une manière de décrire cette page avec le langage HTML serait la suivante:
<html>
<body>
<h1 style="color:red"> L’amanite tue-mouche </h1>
<p> L’amanite tue-mouche est très belle mais très dangereuse ! </p>
<img src="photo.jpg" height="250" />
</body>
</html>
Les éléments de cette page sont indiqués par des balises indiquées par des crochets pointus (<>) et peuvent être imbriqués les uns dans les autres. Ainsi la page (entre <body> et </body>) contient un titre (entre <h1> et </h1>) de couleur rouge, un paragraphe de texte (entre <p> et </p>) ainsi qu’une image (<img>) disponible dans le fichier photo.jpg et de hauteur 250 pixels. Cette page pourra ainsi être affichée de la manière suivante dans le navigateur web.

La plupart des navigateurs web permettent de visualiser le code HTML des pages visitées. Un aspect important de la création de sites web consiste à écrire du code HTML qui sera mis sur le serveur pour être transmis au visiteur du site web. Cela peut se faire en écrivant directement du code HTML dans un fichier texte, ou à l’aide d’un outil de création de sites web qui se charge d’écrire le code HTML selon les indications données par la personne concevant le site.
5.3. Les évolutions du Web¶
Javascript¶
Dans la version originale d’HTML, les moyens d’interagir avec une page web étaient très limités, par exemple cliquer sur les liens que la page proposait. Les personnes utilisant et développant le web ont vite voulu enrichir l’interactivité. C’est pourquoi, en 1995, les développeurs de Netscape, le navigateur web populaire de l’époque, ont ajouté la possibilité d’intégrer des programmes dans les pages web. Ils ont pour ceci inventé un langage de programmation, javascript, qui puisse être interprété et exécuté par le navigateur web. Cela permettait d’avoir une page web avec du contenu dynamique qui réagisse aux actions des personnes utilisatrices, par exemple pour changer la langue du texte lorsque on appuie sur un petit drapeau. Cela permet aussi de programmer des animations sur une page web.
Le Web dynamique¶
Au début, les pages web étaient des fichiers HTML stockés sur les serveurs. C’est ce qu’on appelle le
web statique. Si les sites web statiques existent
toujours, par exemple modulo-info.ch, beaucoup de sites web sont dynamiques,
c’est-à-dire que le fichier HTML est généré par le site au moment où la requête est faite.
Cela permet de servir une page différente selon l’utilisateur ou selon les arguments de la requête. Ces arguments
sont des indications supplémentaires ajoutées après un signe ? à la fin de l’URL.
Micro-activité
Effectuer une recherche sur un navigateur web et consulter la barre de navigation. Quels sont les arguments de votre requête et pouvez-vous en comprendre la signification?
Exercice 1
Parmi les sites web suivants, lesquels ont besoin d’être dynamiques et lesquels peuvent se contenter de fournir un contenu statique?
Un site d’achats en ligne
Un site indiquant les horaires d’ouverture et de fermeture d’un magasin.
Un site de consultation du catalogue d’une bibliothèque
Un site de présentation d’une entreprise
Un site avec les documents d’un cours universitaire ou scolaire
Un site d’e-banking
Pour les sites qui peuvent être statiques, quelles possibilités supplémentaires pourraient être offertes par un site dynamique?
Le Web 2.0¶
Le web 2.0 fait référence à la tendance, initiée au début des années 2000, de proposer des pages web permettant aux internautes de contribuer du contenu, et pas uniquement de lire des fichiers comme c’était le cas jusqu’alors. Les blogs, forums, wikis, et les réseaux sociaux font partie de ce développement qui voit exploser l’aspect participatif du web. Ce n’est en effet plus nécessaire de connaître la syntaxe HTML et d’avoir son propre serveur pour mettre du contenu à disposition des internautes de la planète. Si les développements techniques qui ont permis le web 2.0, étaient peu importants, ils ont eu un effet considérable sur la manière dont la population s’est approprié le web pour en faire un espace d’expression et de partage duquel ont émergé des réseaux sociaux d’aujourd’hui.
Ai-je compris ? – L’exemple d’Alice
Pour demander la page web du site champigons.ch le navigateur web d’Alice va utiliser le protocole HTTP (ou HTTPS) qui spécifie des mots de code indiquant qu’on veut accéder à une page donnée ou envoyer des informations au serveur. Le serveur va répondre avec le même protocole pour envoyer la page ou un message d’erreur si ce n’est pas possible. La page, elle-même, est envoyée au format HTML, c’est à dire sous forme de texte et d’images. Le navigateur va lire ce texte qui va lui indiquer ce qu’il faut afficher pour Alice.